How to Build an AI-Ready Data Architecture for GenAI and Analytics

- Introduction
-
Why AI-Ready Data Architecture Matters
- How to Build an AI-Ready Data Architecture
- Business Benefits of AI-Ready Data Architecture
- Conclusion
- FAQs
Summary
Many companies want to move ahead with AI, but their data often creates problems along the way. It’s usually spread across different systems, not always reliable, and harder to use than expected. That’s where AI-ready data comes into the picture.
In most cases, teams spend a lot of time cleaning and organizing things before they can actually use them. Different teams also look at it in their own way, which can slow things down.
If this isn’t handled properly, it becomes difficult to get real value from AI or even basic analytics.
This blog focuses on what needs attention first, so things become easier to manage and more useful in day-to-day work.
Introduction
Many companies are trying to use AI in their work at the present time. It sounds simple at first, but once they actually start, things slow down pretty quickly. Most of the time, the issue is not the AI tools. It is the data they already have. It is usually spread across different systems and does not always fit together when teams try to use it. Some of it may also be outdated or incomplete, which makes things even harder. So before anything useful happens, a lot of time goes into fixing and cleaning things up.
Different teams also look at this problem in different ways. Some focus on tools, some focus on reporting, but the data side often takes the most effort in real projects. This is usually where AI Data Readiness becomes a real concern. That is where this concept becomes important. It helps structure and prepare data so teams can use it without repeating the same preparation work again and again. It also reduces confusion when multiple systems are involved.
In this blog, we will explore what a well-structured data foundation is and what teams need to address first to use AI effectively in real-world projects.
Why AI-Ready Data Architecture Matters
AI works well only when the data behind it is clean and properly organized. When the data is scattered, incomplete, or doesn’t line up across systems, the results usually become unreliable and don’t add much value.
An AI-ready data architecture is just a way of setting up data so it’s actually usable for AI, machine learning, and GenAI tools. It connects different data sources and keeps things aligned so teams don’t have to keep fixing or cleaning data every time they start something new.
In most companies, data is spread across a bunch of systems. Customer info is in one place, sales in another, and reporting somewhere else. When you try to bring it all together, it rarely fits properly. So a lot of time gets wasted just cleaning and matching things before any real work even starts.
Here, AI data infrastructure helps reduce that mess. It keeps data connected and consistent, so teams can just use it instead of constantly checking whether it’s correct.
It also makes work feel smoother. People don’t have to spend so much time fixing data issues, so they can actually focus on building and improving AI use cases instead of preparing data again and again. And as things grow, data grows too. A proper setup helps keep everything under control so it doesn’t turn chaotic later. In simple terms, it just makes data easier to deal with, so teams can actually use AI without getting stuck in preparation work. Building this foundation often requires strong data engineering capabilities, especially for large-scale systems and pipelines. Organizations typically rely on Data Engineering Services to design and maintain this backbone.

How to Build an AI-Ready Data Architecture
AI projects don’t start with models or tools. They start with understanding and fixing how data is spread across systems. In most organizations, data exists in various platforms and formats, making it hard to use for AI.
Before any real AI work begins, teams bring structure and clarity to this data. At this point, data modernization for an AI enterprise becomes important, helping companies make their existing systems ready for AI use. Once this is done, the process moves into structured steps.
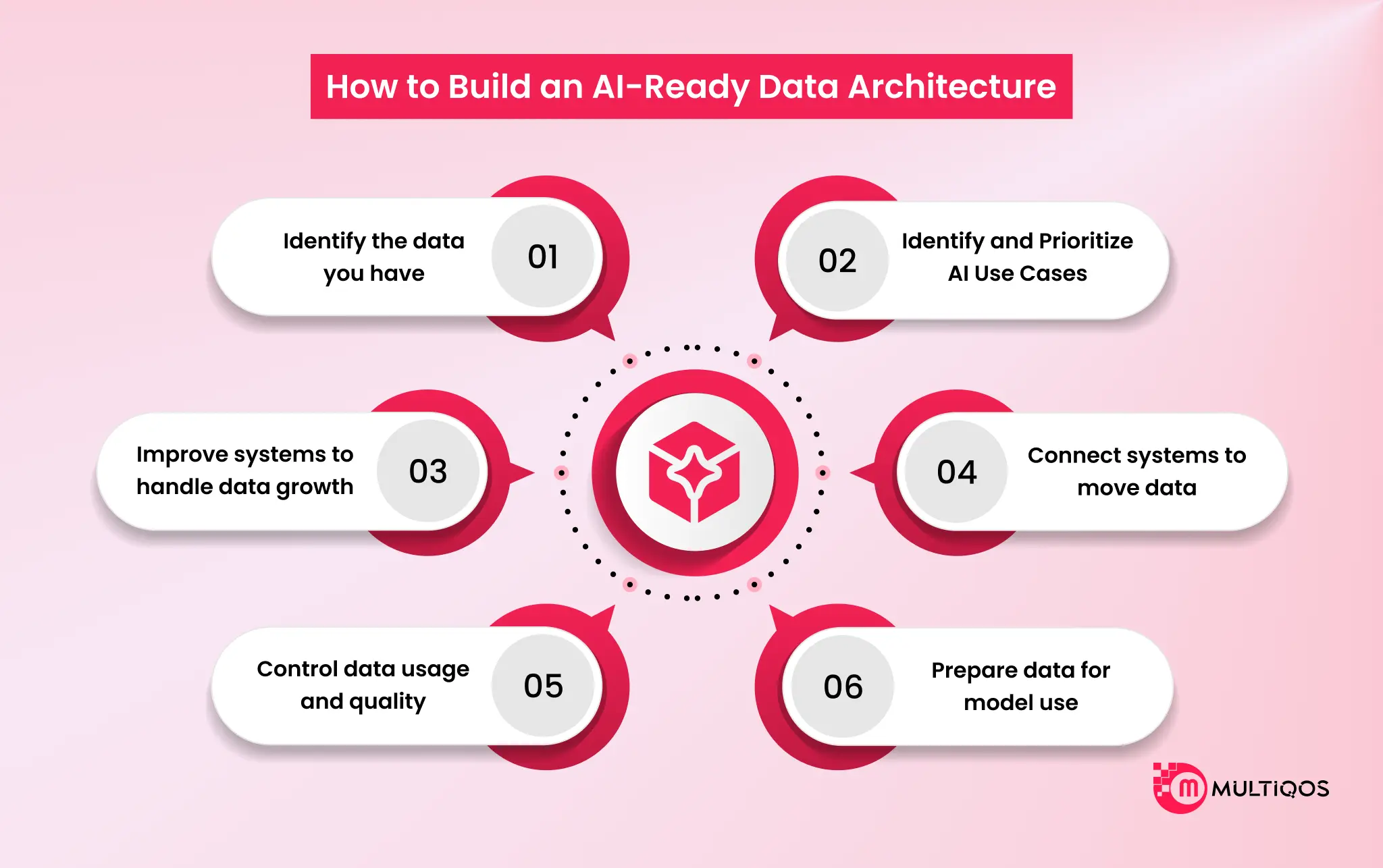
Step 1: Identify the data you have
Most teams check what data actually exists across the organization. They find it spread across databases, SaaS tools, Excel files, and older systems that no one really tracks anymore. As they dig into it, things look messy very quickly. They see duplicate records, missing values, mismatched formats, and outdated data. In many cases, teams even stop and question how reliable the data really is.
Step 2: Identify and Prioritize AI Use Cases
AI is not applied everywhere at once. Teams first figure out what actually matters to the business. Some focus on reducing manual effort, others focus on improving reporting, and some aim to generate deeper insights. In more advanced cases, they explore prediction and risk-based use cases. However, everything depends on one key factor: if the data is weak, the results remain limited. So teams focus only on use cases that match the quality and reliability of available data.
Step 3: Improve systems to handle data growth
As data grows, older systems start to show strain. Things slow down. Queries take longer than they should, pipelines break more often, and suddenly scaling becomes something teams keep dealing with instead of something already solved.
At some point, fixing the old setup just stops making sense. Teams begin shifting the whole structure instead. Cloud or hybrid setups usually come in here because they take away a lot of scaling pain. Along with that, data lakes, lakehouses, or modern warehouses get introduced so the system can handle large volumes and real-time data without constantly failing under load. After that shift, things don’t become perfect, but they become manageable. Data moves better across systems, and teams spend less time fighting infrastructure.
Step 4: Connect systems to move data
Even after system improvements, data often remains distributed. Teams connect these systems to enable seamless data flow across the organization. They implement data pipelines or integrations instead of handling data manually. Data then moves consistently between systems, either on schedules or in continuous flows. This reduces manual effort and improves consistency. This also ensures data consistency across all systems, which supports downstream AI and reporting accuracy.
Step 5: Control data usage and quality
Once data is flowing everywhere, consistency becomes the first real problem. One team pulls one version, another team pulls something slightly different, and nobody notices at first. Over time, trust starts to break. This is where ownership matters. Someone has to actually be responsible for the data; it gets messy very quickly. Access control also becomes important, not just for security, but to stop accidental misuse. Governance shows up in the background but ends up doing a lot of heavy lifting. Privacy rules, compliance, retention, encryption, audit logs, these don’t feel urgent in the beginning, but they become critical once data starts scaling across systems. When this is in place, teams stop second-guessing every dataset. They just use it and move on.
Step 6: Prepare data for model use
Teams usually reach this stage only after everything else is already stable. They don’t start it early because it simply doesn’t work well when systems are still changing. At this point, they take raw data and start fixing it. They clean it, reshape it, and bring it into a format that makes sense when different sources come together. A lot of small issues show up here, so they keep adjusting until the data feels consistent. After some time, doing this manually becomes difficult to manage. So they slowly automate the process in steps. Once that is in place, everything becomes more stable. AI models start working with the data properly, and analytics or GenAI tools don’t keep running into issues caused by messy inputs. Once the data is ready for model use, organizations can start building real-world GenAI applications on top of it.
Business Benefits of AI-Ready Data Architecture
A strong data foundation makes a real difference when people try to use data for AI. Without it, most of the time goes into fixing problems instead of building anything useful.
Here are several benefits companies start to notice once they set this up properly:
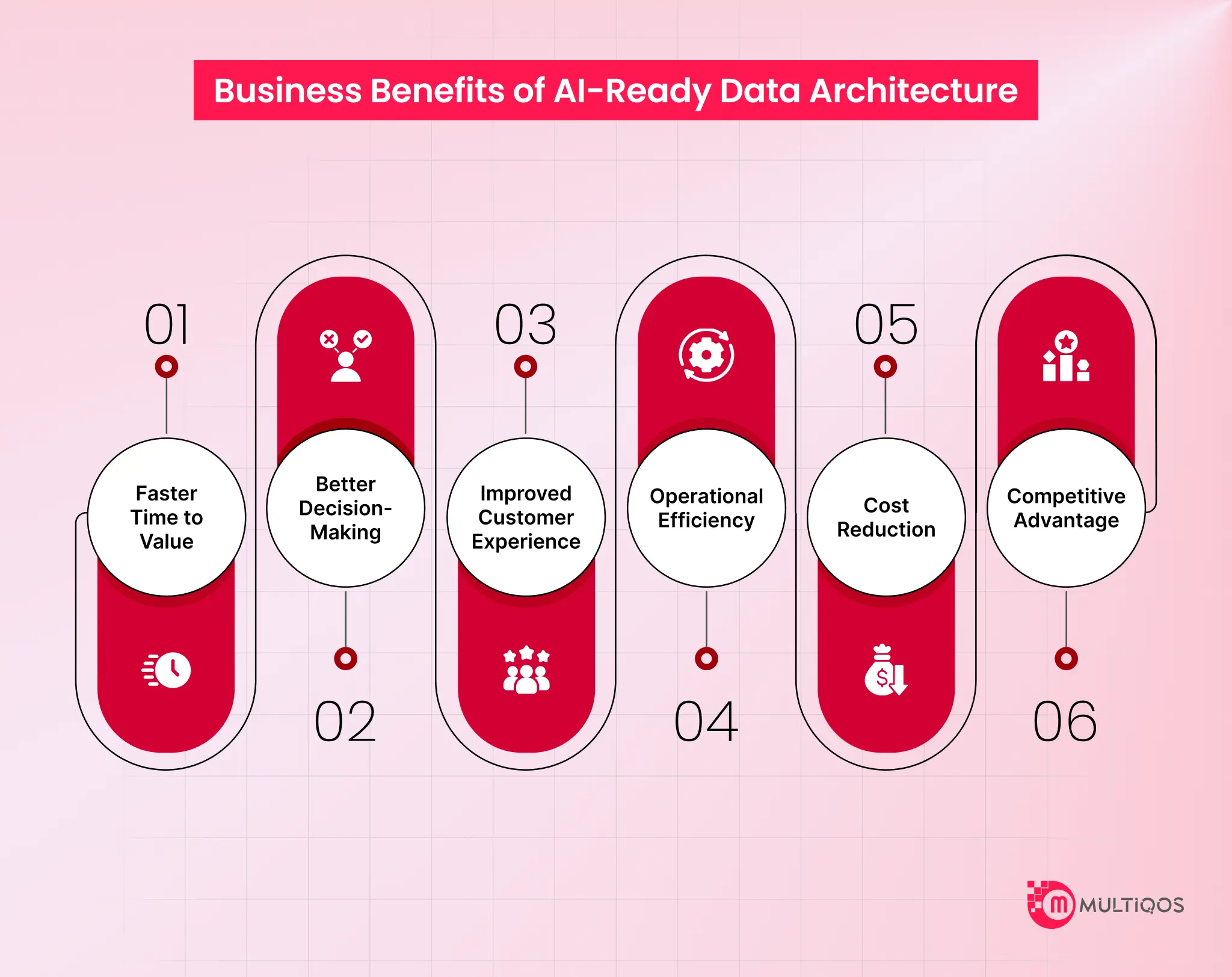
1. Faster Time to Value
Work starts sooner when the data is already usable. People do not repeat cleaning tasks. They move directly to the building and see results earlier.
2. Better Decision-Making
Different systems often show conflicting numbers. This creates confusion and delays decisions. A unified data view removes these issues and supports faster, clearer decisions.
3. Improved Customer Experience
Customer data often stays spread across systems. This limits visibility. Bringing it together helps identify patterns and respond more accurately to customer needs.
4. Operational Efficiency
Daily work includes repetitive tasks such as moving data and fixing errors. These tasks consume time. A structured data setup reduces this effort and improves workflow.
5. Cost Reduction
Cost savings increase over time. Reduced rework, fewer errors, and lower manual effort contribute to lower operational costs.
6. Competitive Advantage
Companies with strong data systems act faster. They test ideas quickly and adjust without delays. This supports a better response to changes in the market.

Conclusion
AI doesn’t fail because of technology. It fails when the data behind it is not in a usable shape. Most companies struggle because their data stored in different systems doesn’t match properly, or takes too much effort to pull together. In that situation, AI takes longer to build and often doesn’t give results people can trust.
Things change when the data side gets organized. Teams don’t waste time fixing the same issues again and again. Data becomes easier to access, and AI work becomes more practical in real business use. At the end of the day, AI only works when the data is already in good shape. That’s what actually makes it useful at scale.
FAQs
When data isn’t ready, AI projects slow down quickly. Teams end up spending most of their time fixing and cleaning data instead of actually building useful AI solutions, and the results often don’t feel reliable.
GenAI and analytics depend heavily on clean and consistent data. If the data is scattered or messy, the outputs lose accuracy and value. Once the data is organized properly, teams can trust the insights and work much faster.
It usually starts by bringing data together from different systems into one place. After that, teams clean up inconsistencies since real-world data is rarely perfect. Then they define simple rules so the data stays usable and consistent over time.
Most companies deal with legacy systems and fragmented data spread across tools. Cleaning and connecting everything takes time, and ownership is often unclear, which leads to different teams handling data in different ways.
Any company that depends on data for decisions or AI will eventually need it. Once GenAI or analytics becomes a priority, having clean and connected data stops being optional and becomes essential.

Get In Touch

Get Stories in Your Inbox Thrice a Month.

AI Chatbot Development Cost in 2026: Build vs. Buy, Phases, and Industry-Wise Pricing

Rethinking Software Delivery through AI Workflow Orchestration: The New Engineering Playbook

AI Agent Frameworks Comparison: LangChain vs LangGraph vs AutoGen vs CrewAI